TurboQuant技术深度解析:向量量化如何重构存储产业底层逻辑
2024年春天,我第一次深入研究大模型推理成本时,发现了一个被业界忽视的关键瓶颈——KV缓存。彼时,市场沉浸在"算力即一切"的狂热中,鲜有人注意到这个隐藏在推理管线深处的内存吞噬者。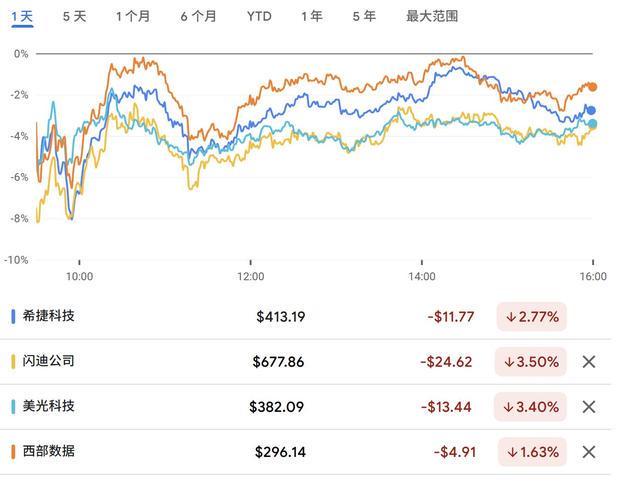
技术解构:从坐标变换到误差修正的双层架构
TurboQuant的核心突破在于其双层优化架构。第一层采用PolarQuant方法,将传统笛卡尔坐标系转换为极坐标系统。数据从"向东3米向北4米"的传统表达,蜕变为"37度角行走5米"的极简形式。通过引入随机旋转机制,数据分布变得可预测,从而彻底摒弃了传统量化方法必需的额外参数存储开销。
第二层则借助QJL技术,仅用1个比特即可精准修正压缩带来的微小误差。这1比特的存在,确保了压缩后的输出精度与原始32位浮点完全一致,不损失任何模型性能。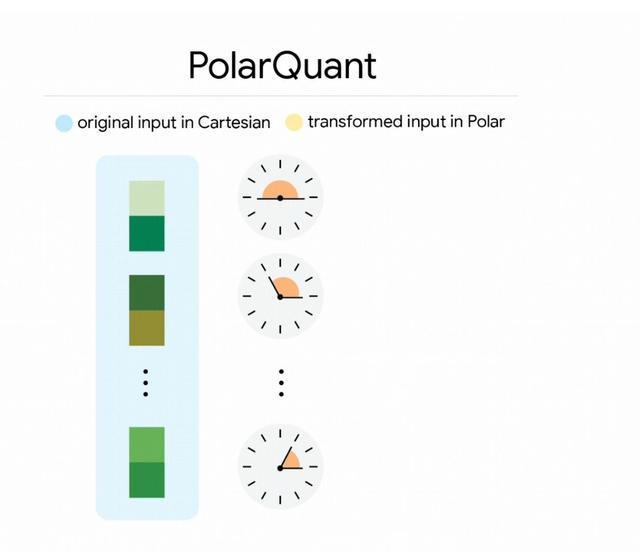
性能实测:83%内存削减与8倍速度提升
在H100GPU上的实测数据揭示了这项技术的真正威力:KV缓存从32位压缩至3比特,内存占用降至原来的1/6,降幅达83%;在Gemma、Mistral等主流模型测试中,性能与未压缩版本完全一致,无需任何额外训练或微调;4比特TurboQuant的注意力计算速度达到32位未量化版本的8倍。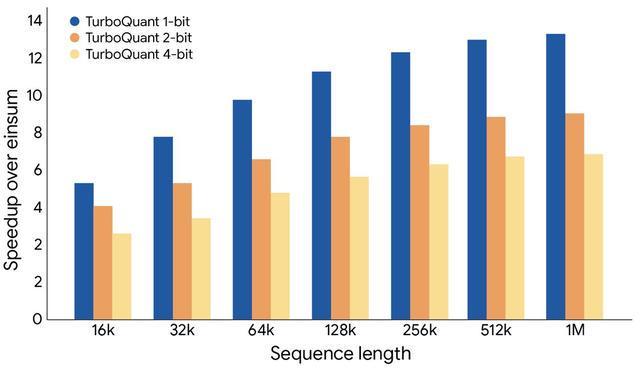
这组数据意味着:一块H100GPU现在能承载的并发推理量,相当于此前的8倍。对于商业化部署而言,这意味着单位服务成本的指数级下降。
市场误读:存储需求≠内存容量需求
然而,市场在解读这项技术时犯了一个根本性错误——将KV缓存压缩等同于整体存储需求下降。摩根士丹利的分析精准指出了这一逻辑漏洞:TurboQuant仅作用于推理阶段的KV缓存,不影响模型权重存储,也不涉及训练环节。
更深层的分析援引了"杰文斯悖论":瓦特改良蒸汽机提高了煤炭利用效率,结果却导致全球煤炭需求飙升。TurboQuant降低单次查询成本后,原本只能在昂贵云端集群运行的模型将迁移至本地设备,AI部署门槛大幅下降反而会刺激更广泛的需求增长。
产业启示:效率革命催生的新均衡
"内存帕金森定律"揭示了存储产业的内在规律:释放出的内存空间从不会闲置,只会被更长的上下文窗口、更大的批处理规模、更复杂的推理需求迅速填满。每一代硬件升级带来的余量,都会在下一代应用需求中消失殆尽。
对于存储产业而言,TurboQuant带来的不是需求拐点,而是效率革命。它加速了存储需求的增长曲线,而非逆转这一趋势。那些在恐慌中抛售的投资者,正在犯一个经典的技术认知错误。